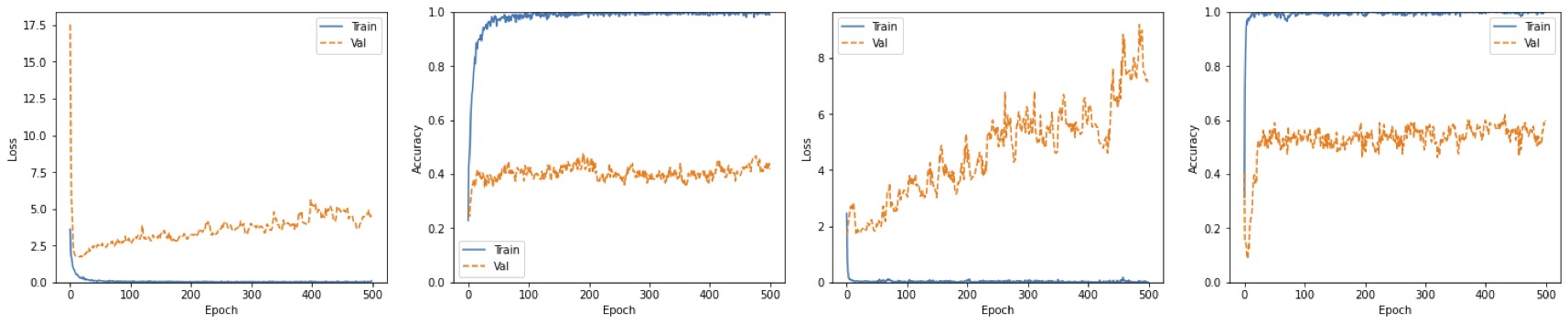
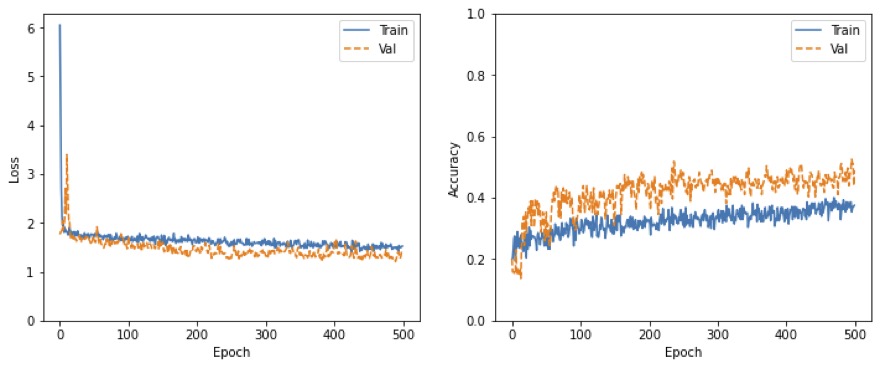
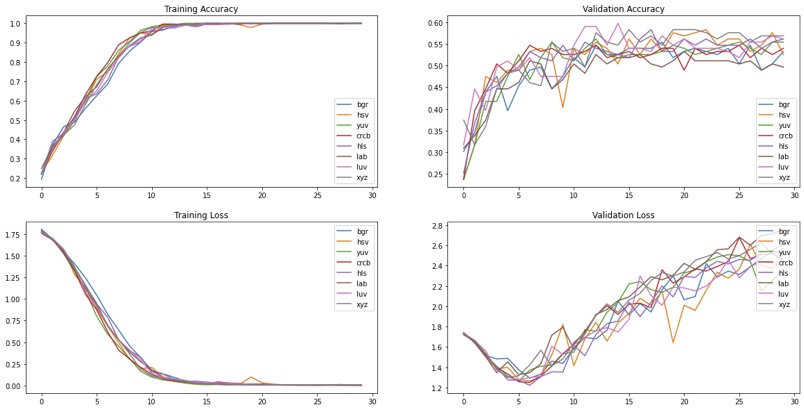
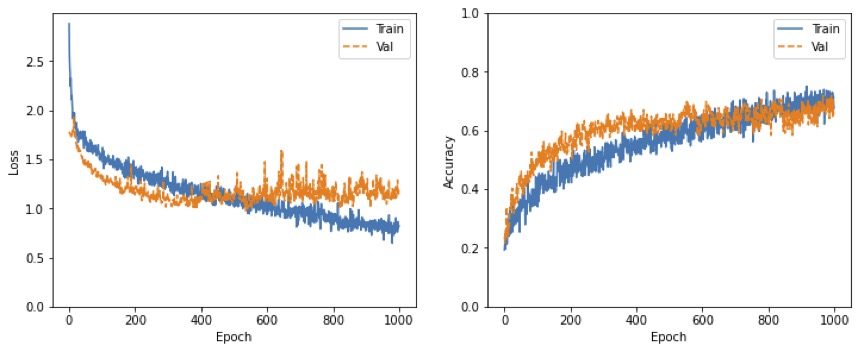
Before we go into the different techniques I tried to improve the acurracy, let's take a step back and go through a few basics.
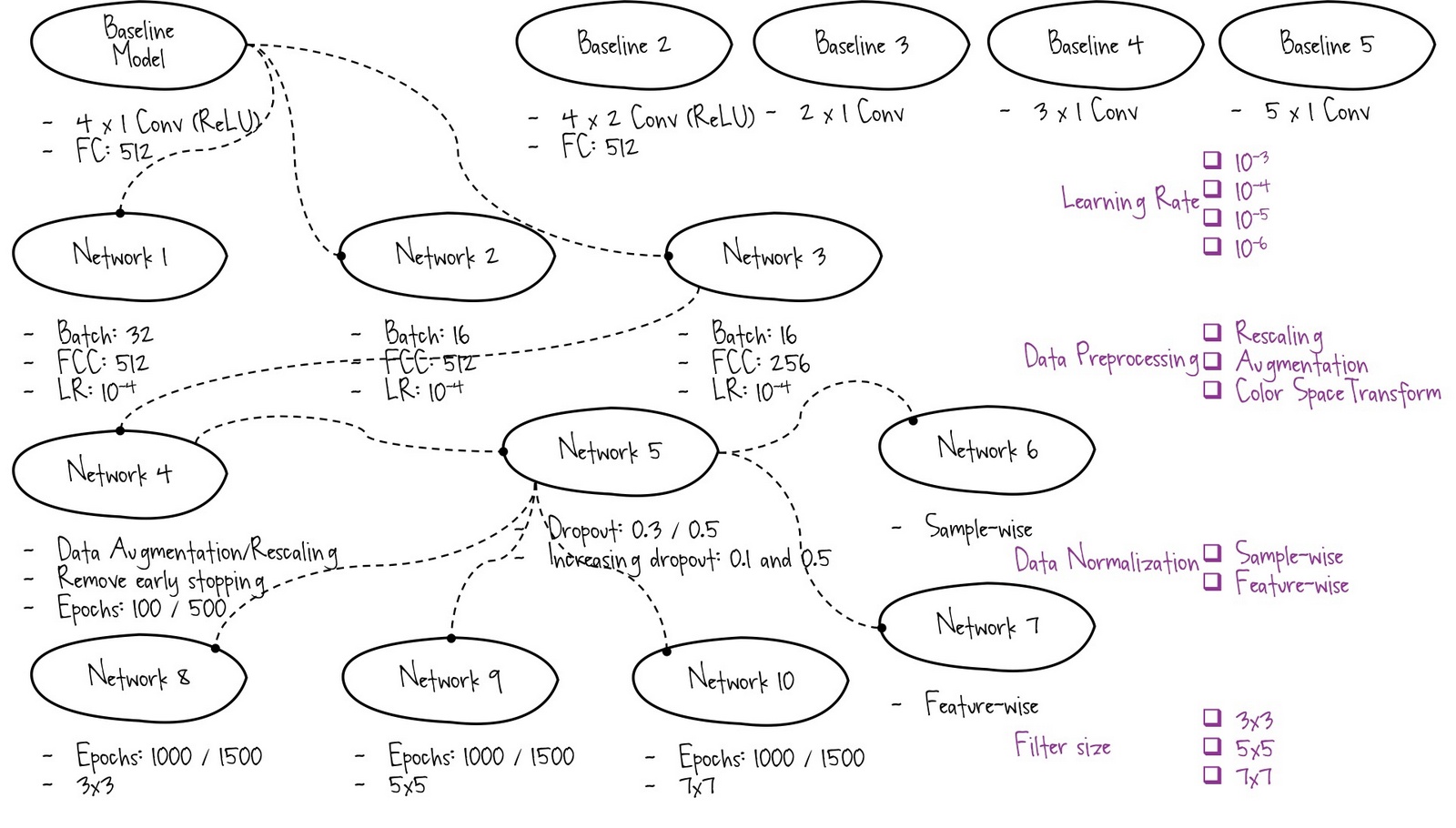
While training a convolutional neural network myself, it can become overwhelming to keep track of all the number of decisions that need to be made and the what seems like almost infinite
possibilities to be explored. This is where pipelines come in handy to experiment with different scenarios. Let's take a quick look at the exploratory data analysis which inspired the pipeline plan.

Analysis:
• The
images are in different sizes
• The
image brightness is fairly random
• The
images may be slightly rotated
• The
images may not be facing straight
• The
images may not be exactly centred
• The
class are fairly equally distributed (most classes ~15% of overall dataset, one class 20% of overall dataset) and
consistent across training, validation and test data set
Visualization helps me to intuitively understand what I’m dealing with. Some ideas I explored here are: resize all images into the same shape, image augmentation to compensate for few training data samples, data normalization, experimentation with different color spaces