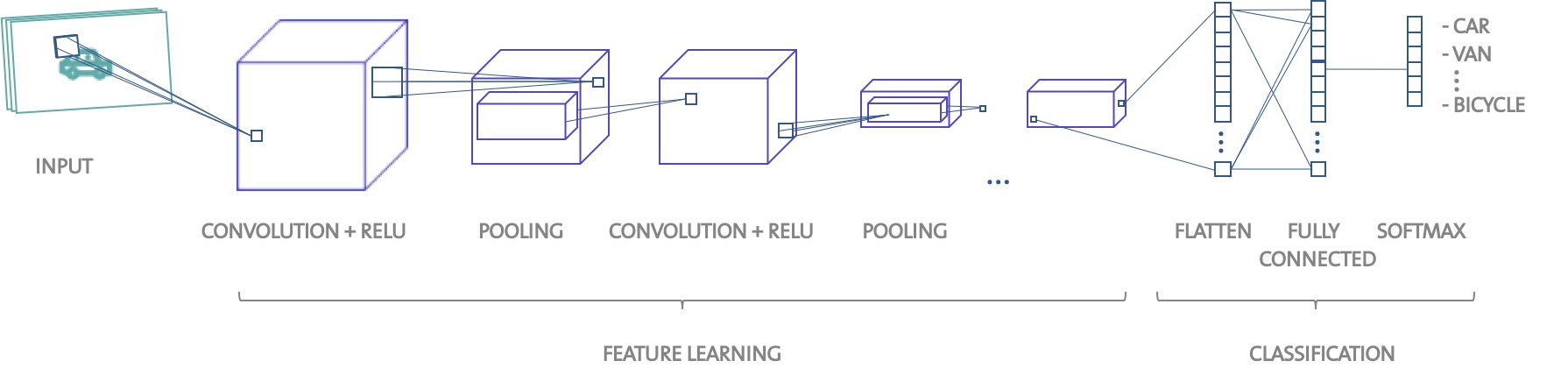
How to Build an Image Classifier with Very Little Data
This project as part of "Applied Data Science: Machine Learning" Program at the EPFL Extension School. I wasn't very happy with the results I got then, so after some more research and the experience of other projects, I decided to revisit it.
One of the projects in the program was to build an image classifier using the Swissroads data
set which contains a couple of hundreds of images of vehicles found in the EPFL
- Lausanne area categorized as cars, trucks, vans, bikes, motorcycles and
others (280 training samples, 140 validation samples). The explicit goals for this
project were one: to test and compare traditional ML classifiers, using transfer learning to get around the problem of very very little data and two: to build a convolutional neural network from scratch trained on the raw pixels ( of the 280 samples). The choice of the machine learning models was given: logistic
regression, decision trees, random forests, support vector machines and
k-nearest neighbors plus convolutional neural networks.